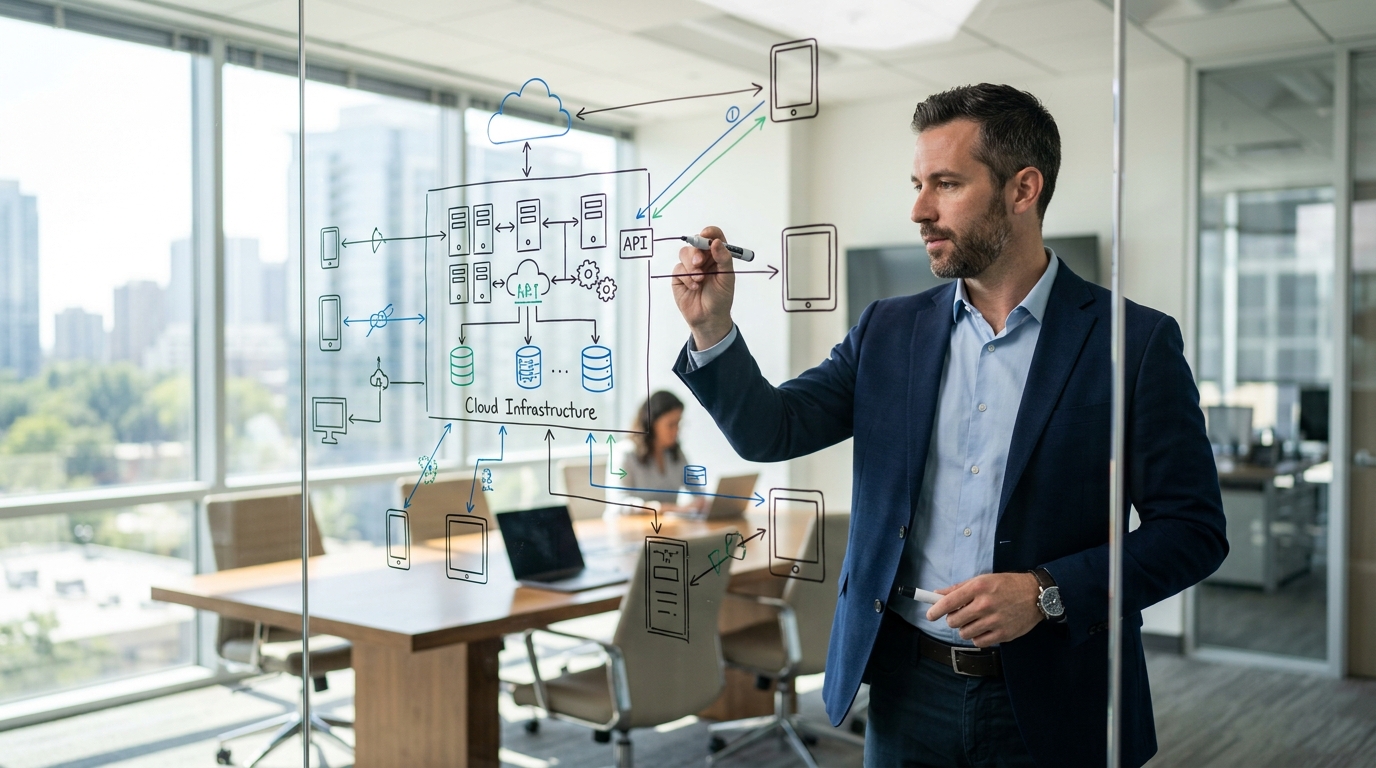
Kostnaden för isolerad programvara
Föreställ dig en operativ chef som står i en livlig flygplatsterminal och försöker färdigställa ett leverantörsavtal innan ett flyg avgår. De bär en äldre iPhone 11 för fälttester och en iPhone 14 Pro för daglig företagskommunikation. För att slutföra denna enda uppgift måste de ladda ner en bilaga från en e-postklient, öppna en separat applikation för att signera den, spara den lokalt, ladda upp den till en molnenhet och sedan manuellt uppdatera ett kundregister i en webbpanel. När de är klara har de interagerat med fyra olika system som inte delar någon underliggande arkitektur. En verkligt effektiv digital portfölj är ett enhetligt ekosystem där applikationer, lagringssystem och datagränssnitt kommunicerar automatiskt och kräver minimal input från slutanvändaren.
Jag ser detta scenario utspela sig hela tiden. Som backend-arkitekt specialiserad på API-design och systemintegrationer granskar jag regelbundet företags teknikstackar som har vuxit fram helt av en slump. Team köper enskilda verktyg för att lösa isolerade problem, vilket resulterar i en fragmenterad röra av överlappande prenumerationer. På SphereApps, ett mjukvaruutvecklingsföretag fokuserat på praktisk nytta, närmar vi oss detta annorlunda. Vi designar vår produktportfölj – som sträcker sig från mobila verktyg till företagsplattformar – för att fungera som en sammanhängande enhet.
Om din organisation utvärderar nya digitala verktyg behöver ni ett strukturerat tillvägagångssätt för att säkerställa att dessa verktyg faktiskt fungerar tillsammans. Här är en steg-för-steg-genomgång av hur man distribuerar en sammankopplad digital portfölj som prioriterar långsiktig nytta och arkitektonisk stabilitet.
Steg 1: Centraliserad dataarkitektur eliminerar friktion i det dagliga arbetsflödet
Det första steget i att utvärdera ett nytt system är att kartlägga hur data ska flöda från användarens händer tillbaka till era centrala servrar. När organisationer tittar på ny mjukvara börjar de nästan alltid med att utvärdera användargränssnittet. Detta är ett kritiskt misstag. Gränssnittet är tillfälligt; datastrukturen är permanent.
För att åtgärda detta måste du prioritera molnlösningar som erbjuder pålitliga, öppet dokumenterade API:er. Om en mobilapp inte omedelbart kan synkronisera sina lokaliserade data tillbaka till din primära databas utan manuell export, skapar den teknisk skuld. Jag rekommenderar att man ritar upp ett diagram över "datans livscykel" innan man skriver en enda rad kod eller skriver på ett leverantörsavtal. Spåra exakt var en bit information uppstår, var den bearbetas och var den lagras permanent.
Den globala mjukvarumarknaden expanderar snabbt – och nådde nyligen 823,92 miljarder dollar enligt Precedence Research – men en alarmerande procentandel av dessa utgifter går till redundant datainmatning. Vi undviker aktivt denna fälla genom att se till att varje produkt vi lanserar delar en gemensam arkitektonisk filosofi. Som Defne Yağız beskrev i sin introduktion till vår metodik, är vår tekniska prioritet att bygga produkter som faktiskt löser underliggande användarproblem, snarare än att bara lägga till brus på deras startskärmar.

Steg 2: Lokaliserad bearbetning skyddar känsliga operationer
När ditt centraliserade dataflöde är definierat är nästa steg att avgöra vad som faktiskt ska hända på själva enheten. Bearbetning av känsliga dokument kräver lokaliserad kontroll, inte konstant serverkommunikation. Varje åtgärd behöver inte skickas fram och tillbaka till en fjärrserver.
Ta dokumenthantering som ett utmärkt exempel. När en anställd ute i fält öppnar en PDF-redigerare på sin mobila enhet för att maskera känslig ekonomisk information eller samla in en kundsignatur, innebär det stora latens- och säkerhetsrisker att skicka den råa filen över ett offentligt mobilnät. Lösningen är edge computing – att köra bearbetningsuppgifterna direkt på den mobila hårdvaran.
Hårdvarans kapacitet har avancerat till den grad att detta är mycket effektivt. Oavsett om en anställd håller i en iPhone 14 eller utnyttjar den större skärmytan på en iPhone 14 Plus för dokumentgranskning, kan de lokala processorerna hantera komplex rendering lokalt. Nyligen genomförd forskning från Cornell University som analyserade 176 AI-drivna appar fann att genom att hålla databearbetningen på enheten säkerställs att känslig information förblir under användarens kontroll. Genom att hålla exekveringen lokal eliminerar du risken för avlyssnad data och påskyndar applikationens svarstid drastiskt.
Din att-göra-punkt här är att granska dina befintliga mobilappar. Identifiera uppgifter som för närvarande kräver en aktiv internetanslutning men teoretiskt sett inte borde göra det, såsom grundläggande dokumentformatering eller offline-datainsamling. Att gå över till lokal bearbetning för dessa uppgifter kommer omedelbart att förbättra användarnöjdheten.
Steg 3: Klienthantering kräver kontextuell leverans med låg latens
Det tredje steget handlar om att strukturera hur stora datamängder presenteras för slutanvändaren. System för klienthantering måste fungera kontextuellt och endast leverera den specifika information som krävs för den omedelbara uppgiften.
Överväg ett typiskt CRM-system för företag. Desktopversioner av dessa plattformar är kända för att ladda hundratals fält, historiska loggar och grafiska paneler samtidigt. Om du försöker replikera den exakta upplevelsen i en mobilapplikation kommer systemet att svikta. År 2026 rapporterar Ericsson att det finns över 8,9 miljarder mobilabonnemang globalt, och även om 5G-nät bär massiva 43 % av den mobila datatrafiken, är bandbredd ingen ursäkt för överdimensionerade API-payloads.
Enligt min erfarenhet av att bygga datapipelines använder de mest effektiva mobila klientapplikationerna mycket selektiva GraphQL-frågor eller anpassade REST-slutpunkter för att hämta endast det som är absolut nödvändigt. Om en säljare går in i ett möte bör appen begära kundens namn, datumet för deras senaste interaktion och aktiva supportärenden. Den behöver inte ladda ner en femårig transaktionshistorik över en mobilmast om det inte uttryckligen begärs.
Bora Toprak gick igenom detta ämne i detalj när han diskuterade vad team faktiskt bör prioritera vid upphandling. Team har inte ett app-problem; de har ett passformsproblem. Om mjukvaran inte respekterar begränsningarna i miljön den verkar i, kommer användarna helt enkelt att överge den.

Steg 4: Intelligenta funktioner kräver precisa interaktionsmönster
Det sista steget i att distribuera en modern portfölj är att integrera maskininlärning och prediktiv logik. AI-integration kräver smart interaktionsdesign; det kan inte vara en efterhandskonstruktion som bultas fast på ett föråldrat gränssnitt.
Många organisationer skyndar sig att lägga till chattgränssnitt i verktyg som inte behöver dem. Om en användare försöker kategorisera ett kvitto eller extrahera text från en bild, är det högst ineffektivt att tvinga dem att skriva ett kommando i ett chattfönster. Istället bör intelligensen arbeta tyst i bakgrunden.
När vi integrerar intelligenta funktioner i våra applikationer fokuserar vi på prediktiv automatisering. Om systemet till exempel känner igen att en användare laddar upp en specifik typ av leverantörsfaktura varje fredag, bör applikationen automatiskt förhandsifylla kategoriseringstaggar och föreslå lämplig godkännandeväg. Forskningen från Cornell University som nämndes tidigare förstärker detta: framgången för AI-verktyg beror i hög grad på hur naturligt de passar in i det befintliga användarflödet. När det implementeras korrekt bör användaren inte ens märka att de interagerar med en AI; de ska bara känna att applikationen är exceptionellt snabb och intuitiv.
Praktiska frågor och svar: Att fatta beslut om implementering
För att sammanfatta detta arkitektoniska tillvägagångssätt, här är praktiska svar på de vanligaste integrationsfrågorna jag får från operativa team.
Hur börjar vi ersätta våra fragmenterade verktyg?
Försök inte göra en massiv migrering över en natt. Börja med att identifiera den främsta flaskhalsen för data – vanligtvis dokumentsignering eller inmatning av kunddata. Implementera en enda, högt optimerad lösning för just den uppgiften, se till att den skriver rent till din databas via API, och fasa sedan systematiskt ut de äldre verktygen.
Diktar vår fälthårdvara våra mjukvaruval?
Mjukvara bör vara konstruerad för att prestera utmärkt på genomsnittlig hårdvara. Om vi utvecklar mobila lösningar ser vi till att backend-logiken och minneshanteringen är tillräckligt snäva för att köras felfritt på enheter som är flera generationer gamla. Om din arkitektur är ren behöver du inte tvinga hela ditt team att uppgradera sin hårdvara bara för att köra ett grundläggande företagsverktyg.
Hur mäter vi om en ny applikation faktiskt är framgångsrik?
Titta på tiden det tar att slutföra en uppgift, inte på dagliga aktiva användare. För nyttoorienterade applikationer är hög tidsanvändning i appen faktiskt ett tecken på misslyckande. Om en anställd tidigare spenderade tio minuter på att formatera och ladda upp ett dokument, och en ny sammankopplad app låter dem göra det på trettio sekunder, är det en framgångsrik implementering. Målet med företagsmjukvara är att flytta sig ur användarens väg så snabbt som möjligt.